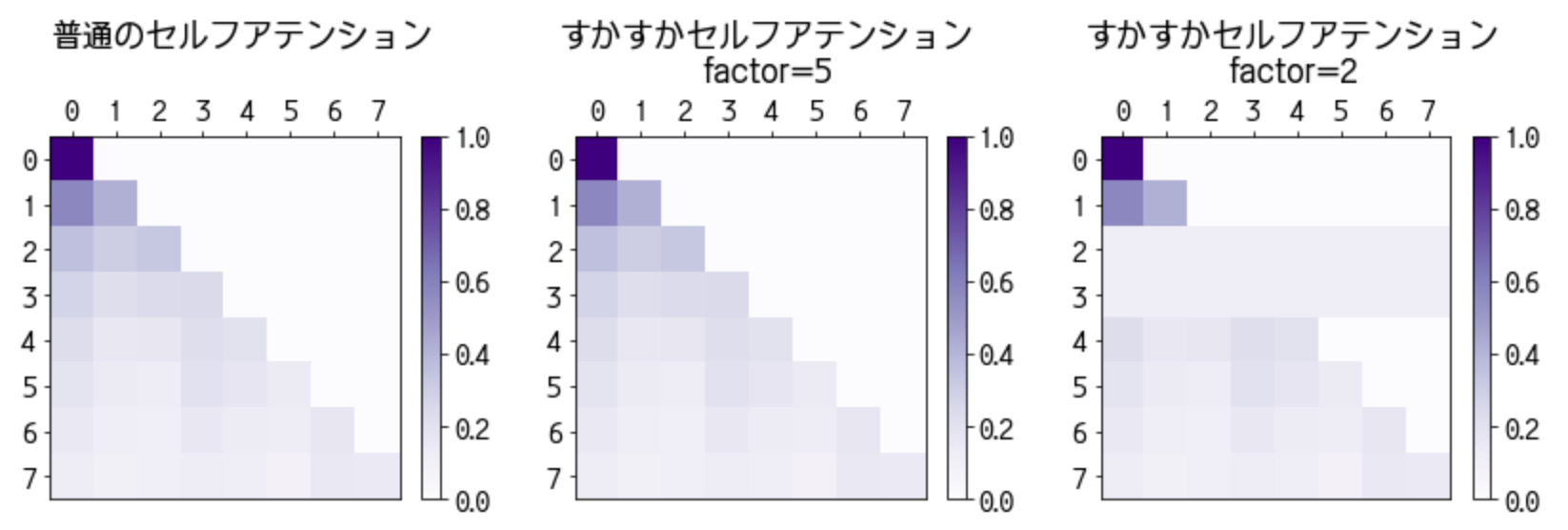
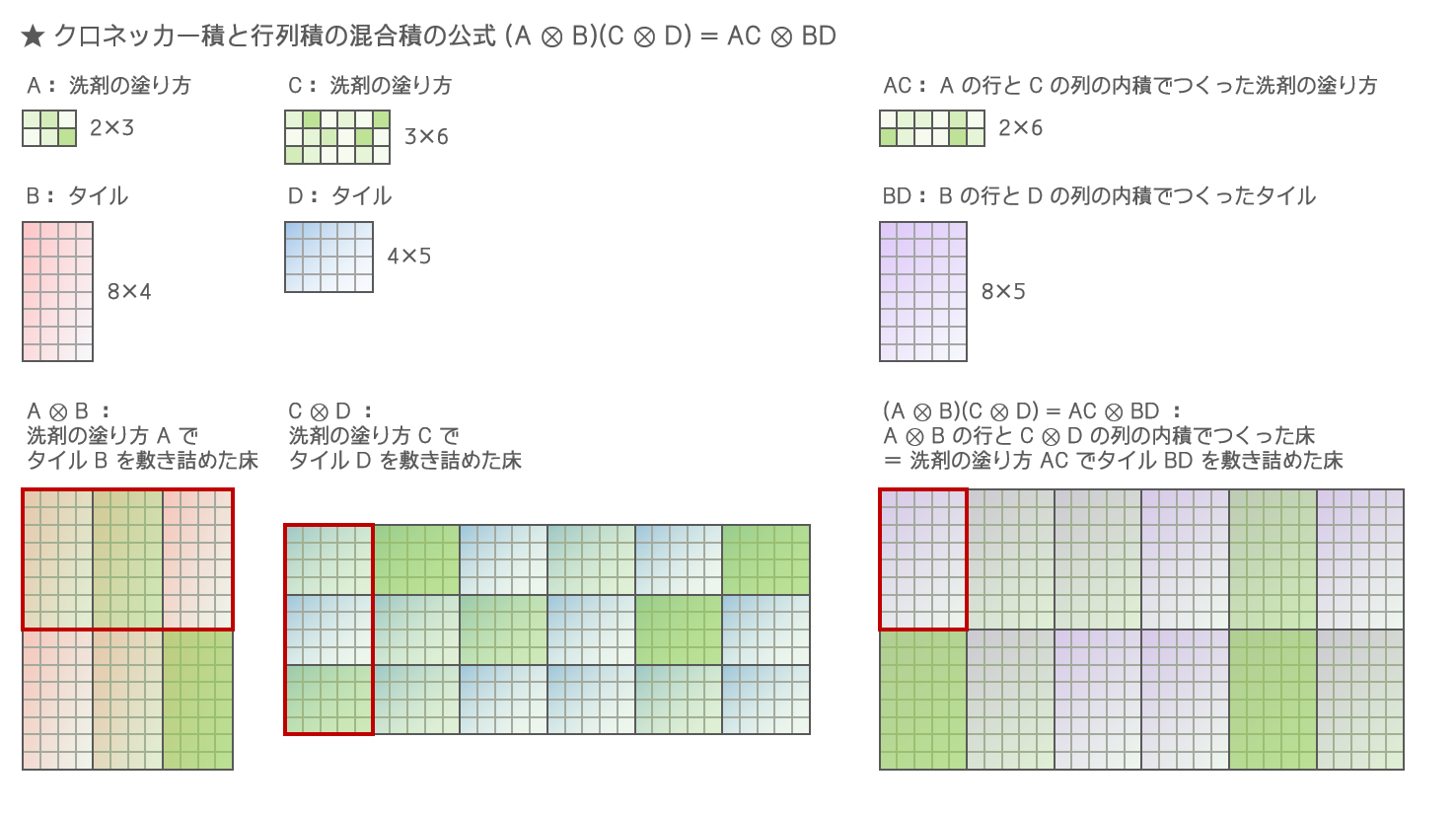
キャラクターの原作とは無関係です。お気付きの点がありましたらご指摘いただけますと幸いです。
 つづいたらつづく
つづいたらつづく
例えば僕たちのカードの中で「焼き芋」に関連するカードを探したいとします。
普通にカードっていうな! メタ世界に触れるのやめて! あと焼き芋に関連するカードなんてあるの!?
アイドルマスターsideM Wiki* で確認できるカード 2229 枚(2021-06-02 現在)のうち、アルバムでの台詞(チェンジ前後含む)に「焼き芋」を含むカードは以下の4枚がありました。
【緋色のパンクロック】秋山 隼人 【白狐演舞祭】若里 春名 【パンキッシュライブ】若里 春名 【秋の妖魔】水嶋 咲
俺だった!!
さらにハヤトのカードの台詞を調べると以下の44単語から構成されていました(助詞や記号をフィルタリングし、各単語は基本形にしています)。うち「焼き芋」の出現回数は1回でした。
'たち': 3, 'うまい': 2, 'やる': 2, 'たい': 2, 'いただき': 1, 'ま': 1, 'ー': 1, 'す': 1, 'アチチ': 1, '熱い': 1, '焼き芋': 1, 'サイコー': 1, (後略)
焼き芋大絶賛だったな俺!? 単語を並べただけで何言ってるかだいたいわかるんだけど…。
なのでこの場合「焼き芋」に対するハヤトのカードの関連度は以下のようになると考えられます。用語は Lucene のドキュメントにしたがいます。
焼き芋
焼き芋
焼き芋