word2vecとGloVeが、前者が predicting で後者が counting といわれたり、結果として得られる「 女王
女王 王
王 女性
女性 男性」という関係式が直感的でめでたしめでたしとなったりしていると思うんですが、どちらも predict しているのではないのかとか、何が直感的なのかとかわからなかったので、word2vecとGloVeが何を目指しているかのメモをかきました。
男性」という関係式が直感的でめでたしめでたしとなったりしていると思うんですが、どちらも predict しているのではないのかとか、何が直感的なのかとかわからなかったので、word2vecとGloVeが何を目指しているかのメモをかきました。
モデルの定式化は全面的に参考文献1. に依っていますが、記事の最初の方と最後の方には私の適当な解釈を多分に含みます。私の誤りは私に帰属します。お気付きの点がありましたらご指摘いただけますと幸いです。
ゴールとして、「もしword2vecが単語類似度タスクに強くGloVeがニュース分類タスクに強い(要出典)のだとしたら、後者は共起行列をつくってから学習し前者はそうでないため、前者は特定の文脈にフィットする解を目指しやすいが後者はあくまで全体の平均を目指し、それゆえに前者は単語類似度タスク(特定の文脈での意味)に強く後者がニュース分類タスク(ニュースを構成する単語全体の意味)に強いのではないか」というような考察を適当ではなくきちんとできるようになりたかったのですが、そこまでいきませんでした。また参考文献1. の 2-7 節に、「単語の分散表現の性能差は各モデルの理論的な側面よりも、実装上の細かいトリックや実験設定に左右されるとの指摘がある.」との記述があります。
参考文献
- 岡崎 直観. 言語処理における分散表現学習のフロンティア(<特集>ニューラルネットワーク研究のフロンティア). 人工知能, 31(2), 189-201, 2016. 言語処理における分散表現学習のフロンティア(<特集>ニューラルネットワーク研究のフロンティア)
- 人工知能学会の学会誌の2016年3月号の記事です。
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., Dean, J. Distributed Representations of Words and Phrases and their Compositionality, Proc. of NIPS, pp. 3111-3119, 2013. [1310.4546] Distributed Representations of Words and Phrases and their Compositionality
- https://code.google.com/archive/p/word2vec/
- word2vecの実装があり、architecture: skip-gram (slower, better for infrequent words) vs CBOW (fast) などのメモがあります。
- Pennington, J., Socher, R., Manning, C.. Glove: Global vectors for word representation, Proc. of EMNLP, pp. 1532-1543, 2014. GloVe: Global Vectors for Word Representation - ACL Anthology
- https://nbviewer.jupyter.org/github/DSKSD/DeepNLP-models-Pytorch/blob/master/notebooks/03.GloVe.ipynb
まとめ(文字の定義は後述)
skip-gram も GloVe も、結局、単語

の周辺(前後

語など、適当に決める)に出現する単語

の分布

を、
内積のエクスポネンシャルによるモデル

でフィッティングすることを通して単語
のベクトル表現

を得ようとするのは共通している。
 のときは
のときは  に他ならない。
に他ならない。 は規格化定数である。
は規格化定数である。 と
と  の比に興味があるときは
の比に興味があるときは  があってもよい(比をとると消える)。
があってもよい(比をとると消える)。
但し、分布間の距離の指標は様々であるし、そもそも語彙数が膨大であるためにこの分布の規格化定数を直接計算するのも現実的ではない。skip-gram と GloVe は何を最小化しようとしてどのように規格化を回避するかが異なっている。
- skip-gram は とし、学習コーパス内に出現するすべての「単語 - その周辺の単語 」の組の条件付き確率
 の対数の和
の対数の和  を最大化するように(∴ 交差エントロピーの重み付き和
を最大化するように(∴ 交差エントロピーの重み付き和  を最小化するように)学習することを目指す。が、規格化の計算が難しいので
を最小化するように)学習することを目指す。が、規格化の計算が難しいので  による2値分類タスクにしてしまう(正例1個につき負例用の周辺単語を
による2値分類タスクにしてしまう(正例1個につき負例用の周辺単語を  個サンプリングする)。
個サンプリングする)。
- CBOW(その名の通り周辺の単語を先に「カバン」に入れて=足してしまう)はこの最適化をさらに簡略化したものとも捉えられる。
- GloVe は
 であることに着目して、「 を でフィッティングするタスク」を、「
であることに着目して、「 を でフィッティングするタスク」を、「  を
を  でフィッティングするタスク」に読み替える。損失は2乗誤差を採用するが、あまり発生しない「単語 - その周辺の単語 」の組に対しては重みを小さくするようにする。
でフィッティングするタスク」に読み替える。損失は2乗誤差を採用するが、あまり発生しない「単語 - その周辺の単語 」の組に対しては重みを小さくするようにする。
- そのため、予め
 のテーブルを用意しておくことになる。
のテーブルを用意しておくことになる。
いずれにせよ、skip-gram や GloVe で得たベクトルは「
内積が対数確率をオフセットしたもの」という性質をもっている。
内積は分配則が成り立つ(和の
内積は
内積の和)ので、

は「周辺の単語の対数確率が単語

の周辺の対数確率と単語

の周辺の対数確率の和になるような仮想的な単語のベクトル」と捉えられる。となると、
 王女性男性
王女性男性 というベクトルをもつ仮想的な単語が考えられるが、
女王 がそれに近かったという事実は、「女王」の周りの分布がそのように「王」「女性」「男性」の分布で特徴付けられるということに他ならない。
word2vecのモデル
- 学習コーパスを単語列
 とする。
とする。
- 単語
 を中心語とした前後 語の文脈窓を
を中心語とした前後 語の文脈窓を  とする。
とする。
word2vecでは、
文脈窓  を与えたときの中心語の確率分布
を与えたときの中心語の確率分布  を、 内の単語のベクトルを用いてモデリングすることを通して、単語のベクトル表現を獲得する。
を、 内の単語のベクトルを用いてモデリングすることを通して、単語のベクトル表現を獲得する。つまり、長さ

の単語列を与えたときに、それらの単語のベクトル表現を用いてどんな単語がその中央にはまりそうかの分布を出すことを目指すのだが、
個の単語の情報をどう集約するかで流派が分かれる(下図)。
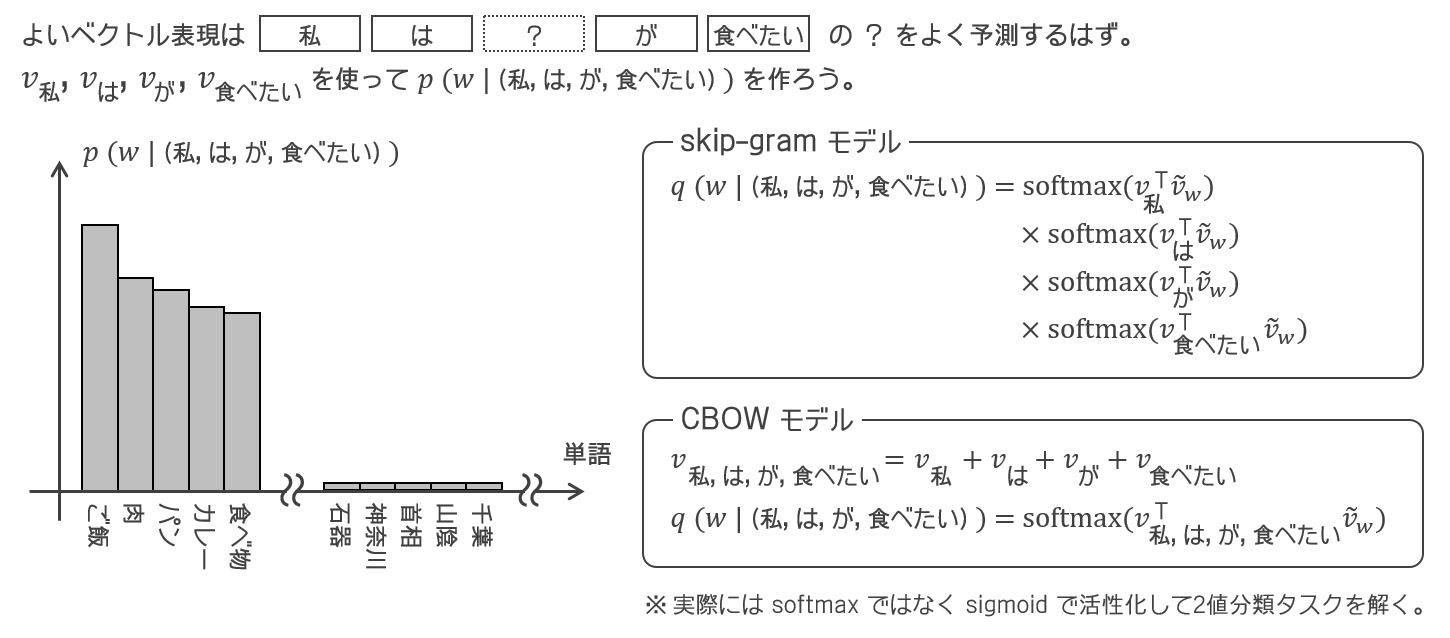
- skip-gramでは を
 でモデリングする。
でモデリングする。
つまり、「文脈窓の中心にどんな単語がきそうか」を、文脈窓内の各単語の「この単語がいる文脈窓の中心にどんな単語がきそうか」の積で表現する(先に各単語からの確率を出して積をとって集約する派)。
- CBOWでは を
 でモデリングする。
でモデリングする。
つまり、「文脈窓の中心にどんな単語がきそうか」を、文脈窓内の全単語のベクトルの和で表現する(先に全単語のベクトルを和に集約してから確率を出す派)。
但し実際にはソフトマックスではなくシグモイドで活性化し、サンプリングした負例との2値分類を学習する。
skip-gram
skip-gramでは

と考える。
はいわば「単語
を与えたときに単語
が単語
のいる文脈窓の中心語である確率」になる。この
をモデル
でフィッティングする。ただし、
は単語
の文脈語としてのベクトル、

は単語
の中心語としてのベクトルであり、全単語にこれらのベクトルをどう用意すべきかがフィッティング対象となる。損失関数は以下とする(学習
コーパス内のすべての中心語-文脈語の組の確率の積を最大化する=対数確率の和を最小化する)。

但し実際には全単語

上でソフトマックスをとることは難しいので損失関数を少し変更する。「文脈語
から中心語
を当てる

値分類タスク」ではなく「文脈語
と中心語
が正しい文脈語と中心語の組かどうか当てる

値分類タスク」と考えることにして、活性化関数をソフトマックスからシグモイドに取り換える。このタスク設定にすると負例が必要になるので、中心語-文脈語の組1つにつき、負例のための中心語

を
回サンプリングする(単語のユニグラム分布からサンプリングする)。

この損失関数を最小化するように学習し、各単語の文脈語としてのベクトル
をその単語のベクトル表現とする。
CBOW(continuous bag-of-words)
文脈窓
に対して、文脈窓内の単語の文脈語としてのベクトルの和を

とする。CBOWでは

と考える。損失関数は以下となる。

但し実際には全単語
上でソフトマックスをとることは難しいので skip-gram 同様に損失関数を変更する。

GloVeのモデル
GloVeでは、
2単語のベクトルの差でそれぞれの単語の周辺に出現する単語の確率分布の比をモデリングすることを通して、単語のベクトル表現を獲得する。但し、「周辺に出現する単語のベクトルと
内積をとった上でエクスポネンシャルをとる」というモデルにしたため、結局、個々の単語の確率分布を
モデリングすることになっている。

具体的に、
- 単語
 の周辺に単語
の周辺に単語  が出現した回数を
が出現した回数を  とする。
とする。
- 単語 の周辺に任意の単語が出現した回数を
 とする。
とする。
- 単語 の周辺に単語 が出現する確率は
 となる。
となる。
が、確率分布

そのものは、どんな単語の周辺にもよく出現するような単語
で大きくなるため、単語
のよい特徴になっていない。それよりも、他の単語

の分布との比を取った

の方が単語
の単語
との関係のよい特徴になっている。ので、確率分布の比
を

で
モデリングすることを目指す。ここで、

の関数形に以下を仮定する。
 に依存する項は の差
に依存する項は の差  にのみ依存する。
にのみ依存する。- をスカラーに変換するにあたり
 との内積
との内積  をとる。
をとる。
- を確率分布の比に変換するにあたり、和を変換したものが変換したものの積になるように
 を採用する(同じ単語どうしの確率分布の比は常に1にならなければならない)。
を採用する(同じ単語どうしの確率分布の比は常に1にならなければならない)。
よって、

となるが、そうなると
を

で
モデリングすることになるので、
を

で
モデリングすることと同じである(

は
にのみ依存する係数)。さらに、
を利用すると、

を

で
モデリングすることになる。損失は2乗誤差を採用する。

但し、

は共起頻度が小さいペアの重みを小さくするための因子で、例えば以下(共起頻度が100回未満のペアの重みを徐々に軽くする例)が用いられる。

得られたベクトル表現の性質
これらの手法で得られた単語のベクトル表現は、モデルより、別の単語のベクトル表現との
内積が意味をもつ(対数確率をオフセットしたものになる)。もし

であれば、
 が、単語
が、単語  が単語 の周辺にいそうな度合いになる。
が単語 の周辺にいそうな度合いになる。 が、単語 が単語 の周辺にいそうな度合いになる。
が、単語 が単語 の周辺にいそうな度合いになる。 は、それらの差になる。
は、それらの差になる。
 女性男性
女性男性 スカート は、正になりそう(※ 適当な例)。
スカート は、正になりそう(※ 適当な例)。- 女性男性ズボン は、負になりそう(※ 適当な例)。
 は、単語 が単語
は、単語 が単語  の周辺にいそうな度合いに先の差を足したものになる。
の周辺にいそうな度合いに先の差を足したものになる。
- 王女性男性スカート は、「王」の文脈に「スカート」がいそうな度合いを大きくしたもの。
- 王女性男性ズボン は、「王」の文脈に「ズボン」がいそうな度合いを小さくしたもの。
- 同様に、任意の単語 について、王女性男性
 は、「王」の周辺に がいそうな度合いに、「女性」の周辺に がいそうな度合いを足して、「男性」の周辺に がいそうな度合いを引いたもの。
は、「王」の周辺に がいそうな度合いに、「女性」の周辺に がいそうな度合いを足して、「男性」の周辺に がいそうな度合いを引いたもの。
word2vecで(GloVeでも)
女王王女性男性 となることがよく知られているが、それは、任意の単語
について、「女王」の周辺に
がいそうな度合いが、「王」の周辺に
がいそうな度合いに「女性」の周辺に
がいそうな度合いを足して「男性」の周辺に
がいそうな度合いを引いたものに近くなっていることを示唆しているのに他ならない。


は
となる。

:
の第
成分に依存する項。
:
の第
成分に依存する項。