お気付きの点がありましたらご指摘いただけますと幸いです。

![\displaystyle {\rm CE}_i = \frac{1}{L} \sum_{j=1}^L \left[ \log \frac{\sum_{j'=1}^L \exp(q_i \cdot k_{j'} / \sqrt{d})}{\exp(q_i \cdot k_j / \sqrt{d})} \right] = \log \left[ \sum_{j=1}^L \exp \left( \frac{q_i \cdot k_j}{\sqrt{d}} \right) \right] - \frac{1}{L} \sum_{j=1}^L \frac{q_i \cdot k_j}{\sqrt{d}}](https://chart.apis.google.com/chart?cht=tx&chl=%5Cdisplaystyle%20%7B%5Crm%20CE%7D_i%20%3D%20%5Cfrac%7B1%7D%7BL%7D%20%5Csum_%7Bj%3D1%7D%5EL%20%5Cleft%5B%20%5Clog%20%5Cfrac%7B%5Csum_%7Bj%27%3D1%7D%5EL%20%5Cexp%28q_i%20%5Ccdot%20k_%7Bj%27%7D%20%2F%20%5Csqrt%7Bd%7D%29%7D%7B%5Cexp%28q_i%20%5Ccdot%20k_j%20%2F%20%5Csqrt%7Bd%7D%29%7D%20%5Cright%5D%20%3D%20%5Clog%20%5Cleft%5B%20%5Csum_%7Bj%3D1%7D%5EL%20%5Cexp%20%5Cleft%28%20%5Cfrac%7Bq_i%20%5Ccdot%20k_j%7D%7B%5Csqrt%7Bd%7D%7D%20%5Cright%29%20%5Cright%5D%20-%20%5Cfrac%7B1%7D%7BL%7D%20%5Csum_%7Bj%3D1%7D%5EL%20%5Cfrac%7Bq_i%20%5Ccdot%20k_j%7D%7B%5Csqrt%7Bd%7D%7D%20)
 についてこの
についてこの  を計算してこれが大きい
を計算してこれが大きい  行を残せば計算量を節約でき…って、これを計算するのにすべての
行を残せば計算量を節約でき…って、これを計算するのにすべての  が必要ですよね? これでは計算量
が必要ですよね? これでは計算量  じゃないですか…。
じゃないですか…。 を計算するんじゃなくて、
を計算するんじゃなくて、 のうち sample_k 行だけ残した
のうち sample_k 行だけ残した  で代用している。いや、正確にいうと、
で代用している。いや、正確にいうと、 の各行に対して sample_k 行の選び方を変えているから、
の各行に対して sample_k 行の選び方を変えているから、 通りの
通りの  を用意して、以下の もどきを計算して、これに基づいて
を用意して、以下の もどきを計算して、これに基づいて  が大きい n_top 行を選んでいるね(※ この記事では の 行目を縦ベクトル
が大きい n_top 行を選んでいるね(※ この記事では の 行目を縦ベクトル  と考えているから横ベクトルに戻すために転置しているよ)。
と考えているから横ベクトルに戻すために転置しているよ)。
- Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, Wancai Zhang. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. arXiv preprint arXiv:2012.07436, 2020.
[2012.07436] Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
GitHub - zhouhaoyi/Informer2020: The GitHub repository for the paper "Informer" accepted by AAAI 2021.
Transformer は行列 によって入力の特徴系列を「前後の文脈を考慮した」特徴系列に変えますが、系列長
が長くなるほどこの行列を用意して適用するのに
の計算量がかかってしまうのですよね? 文脈を考慮する先が増えるわけですから当然ですが。しかし、それでも何とか計算を間引いて Transformer に長い系列を流したいこともあるわけです。そのような手法としてこれまでどのようなものが提案されてきたのでしょう? それぞれの手法にどのような得手不得手があるのでしょうか?
Transformer の1ヘッドがやること
を受け取る.
,
,
を計算する.
を計算する(※ Softmax は各行を正規化する).
なるほど…一様分布と 行目の交差エントロピーは、
行目の確率分布に最適化した情報量の尺度で一様分布を受け取ったときの平均的な情報量…
の
行目
と
の
行目
を縦ベクトルと考えると、
…うーんでも、その主張だと結局 と
を比較するのに
の
行目と
行目が完全に必要になりませんか? それでは意味が―
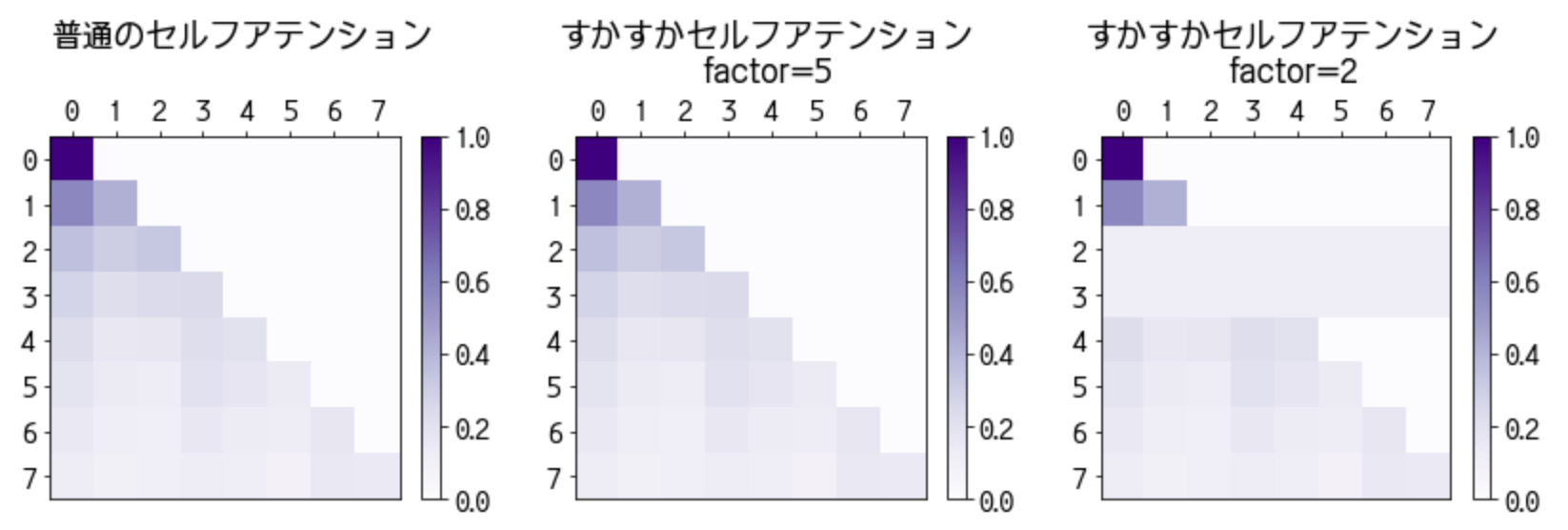
以下の実装をみると を完全に計算しているわけではないね。
https://github.com/zhouhaoyi/Informer2020/blob/main/models/attn.py#L47-L68