[2012.07436] Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
GitHub - zhouhaoyi/Informer2020: The GitHub repository for the paper "Informer" accepted by AAAI 2021.
- セルフアテンションする以上、系列長
に対して
の計算量がかかる。
- セルフアテンション層を積み重ねる原理上、推論時に膨大なメモリを要する。
- 推論に時間がかかる(再帰的にデコードするため)(誤差の蓄積の問題もある)。
- 「ProbSparse」というセルフアテンション手法で特徴抽出性能を維持しつつ計算量を
に抑えた。
- 方針として、
の各行のうち一様分布からの逸脱度が大きい行(=重要な「注意」を含んでいる見込みが高い)だけを残し他の行は捨てる。サンプリングによって逸脱度を見積もる。
- セルフアテンション層を出る度に Conv1D + MaxPool1D して系列の長さを半分にしていくことでメモリ使用量を抑えた(セルフアテンション蒸留)。
- 再帰的にデコードするのではなく一気にデコードすることで推論速度を大幅に向上させた(生成的デコーダ)。
- 「ProbSparse」によるセルフアテンションの有効性の検証として、「通常のセルフアテンション」「Reformer のセルフアテンション」「LogSparse Transformer のセルフアテンション」に置き換えたモデルとも比較されたが、やはりほとんどのタスクでこれらのモデルよりも高い精度を示した。特に、通常のセルフアテンション(計算量大)よりもむしろ精度がよいケースが多かった(=「ProbSparse」による取捨選択が功を奏した)。
- セルフアテンション蒸留の有効性の検証として、セルフアテンション蒸留しないモデル構造とも比較されたが、入力系列の長さが同じであれば蒸留しないモデルの方が精度が出るが、蒸留しないモデルでは入力系列を長くするとアウトオブメモリーになるので、結局セルフアテンション蒸留をした方がよかった。
- 生成的デコーダの検証として再帰的にデコードするモデルとも比較されたが、再帰的にデコードするモデルでは誤差が大きすぎた。
- 提案した3コンポーネント全ての有効性を示している。
- セルフアテンションの計算量の削減の仕方が、先行研究の LogSparse Transformer のように「近くは綿密に計算するが遠くにいくほどどんどんとばす」という幾分アドホックなものではなく、積極的に何かを強く注意している行を優先して残そうとするものになっている。その有効性は通常のセルフアテンションの予測性能を上回っていることで示されている。
- NeurIPS2020 の Adversarial Sparse Transformer は Transformer を敵対的に学習することで長期予測における誤差の蓄積を回避したが、そもそも再帰的に予測したいという要請がなければ Informer のように一度に予測すればよいと考えられる。
導入

この「Informer」は「Transformer による時系列の長期予測」とのことですが、つい最近も「Transformer による時系列の長期予測」をみた気が…以下の「AST(Adversarial Sparse Transformer)」ですね。
NeurIPS2020読みメモ: Adversarial Sparse Transformer for Time Series Forecasting
「AST」が工夫した点は α-entmax を用いてアテンションを疎にし重要な情報をこそ注意するようにした点と、ネットワークを GAN の要領で敵対的に学習した点でしょうか。遠い未来の予測値はそこに至るまでの予測値の系列を再帰的に利用して生成するわけですから、あたかも本物と見紛うような予測値の系列を生み出す必要があるわけで、GAN を用いて学習するというのはイメージとして合っているような気がします。他方、こちらの「Informer」はやはり Transformer が遠い過去の情報を掴めることを利用しているわけですが、Transformer を時系列に応用するにあたって以下が問題だといっていますね。
- セルフアテンションする以上、系列長
- セルフアテンション層を積み重ねる原理上、推論時に膨大なメモリを要する。
- 推論に時間がかかる(再帰的に推論するため)。

していなかった気がするけどな…でも、Transformer を時系列に応用するにあたってその系列長に関する計算量のボトルネックを何とかしようという話ならむしろ NeurIPS2019 にあったよね。以下の記事の中の「Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting」かな。このモデルの通称は「LogSparse Transformer」だね。
雑記: NeurIPS 2019 Proceedings の「時系列」を含むタイトル
趣旨が同じだから当然「Informer」からも「LogSparse Transformer」は引用されているね。というか6ページ目の検証結果の Table 1 や Table 2 内で「LogTrans」とされて比較手法になっているね(今回の提案手法でのセルフアテンションの仕方の有効性を確かめるためにセルフアテンションの仕方だけを置き換えた形だと思うけど)。表をみると「LogTrans」は Table 2 の多変量時系列予測部門の ECL データセットの1週間後、2週間後予測で優勝しているね。他の予測でも提案手法に肉薄している気もするけど。うおお勝手に先を読まないでください。アブストラクトに戻ると今回の「Informer」は上記の問題に対し、
- 「ProbSparse」なるアテンション手法で特徴抽出性能を維持しつつ計算量を
- 「セルフアテンション蒸留」で系列長を削減していくことでメモリ使用量を抑えた。
- 「生成的デコーダ」によって1ステップでの長期予測を達成し推論速度を大幅に向上させると共に、誤差の蓄積も抑えた。
私にいわれましても…まあそれで、遠い過去の情報を活用するとなると、過去の入力を再帰を介さずに直接「注意」しにいける Transformer に白羽の矢が立つわけですが、先に述べた通りの難点があるわけです。「セルフアテンションの威力がこそボトルネックになってしまう」と…いや何のデメリットもなくおいしい話はそうないと思いますが…。ともかくそのボトルネックを何とかしようとしにいくわけですが、何もボトルネックを何とかしようという研究はこれまでもあったわけです。列挙されているものは以下ですね。
| Sparse Transformer(Child et al. 2019) | Transformer を画像にも適用しているんですね。これは論文の3ページ目の Figure 3. をみるに、アテンションの行列 |
|---|---|
| LogSparse Transformer(Li et al. 2019) | これは件の NeurIPS2019 の論文ですね。5ページ目の図をみるに、これもアテンションの行列 |
| Reformer(Kitaev et al. 2019) | これも計算量を |
| Linformer(Wang et al. 2020) | セルフアテンション内での射影の行列を低ランク近似することで |
| Transformer-XL(Dai et al. 2019) | これらは「補助隠れ状態」を用いることで計算量を抑えつつ遠い過去の情報を利用できるようにしたようですが、であれば今回用いられたアプローチとは違いますね。これらのアプローチは時系列には応用できるのでしょうか…? |
| Compressive Transformer(Rae et al. 2019) |
問題点の 3. は長期予測に独特だからともかく、2. の必要メモリへの取り組みはあったんじゃないのかな。そのまま「蒸留BERT」なるモデルが公開されていて Linformer でも引用されているし、さらに「貧乏人のためのBERT」なんていう論文もあるよ。今回の手法とは枠組みが違うのかな?
BERT を動かせない人が貧乏なのではありません、BERT を動かせる計算資源を利用できる人がお金持ちなのです…。
モデル
気を取り直してモデルの詳細に入りましょう。まずモデルの入出力は、
- モデルの入力は
次元ベクトルが
個並んだもの
です。
- モデルが出力すべきは
次元ベクトルが
個並んだもの
です。つまり、長期予測といっても、遠い未来の1点ではなく、遠い未来までのすべての点の予測を目指すということを含意していると思います。

うん、自然言語処理では普通「文章長さ < 特徴次元数」だからその図の入出力みたいに横長の長方形になるわけだよね。でも今回は長期予測をしたいから、Table 1, Table 2 にある数値の単位がステップ数で合っているなら予測部分だけで960ステップ流したいことになるよね。BERTには256ステップ以上流せない設定になっているくらいだから、長いわけだね。計算量は流すステップの長さを とするなら
の部分の行列積が
で、最後のアテンションを適用するときの行列積が
だから、
を定数扱いすれば
だね。
ええまさにそのような話が続きます。なので計算量が になることを割けるべく、これまで Sparse Transformer や LogSparse Transformer は行列
(面倒なのでこれ以降セルフアテンション行列とよびます)の成分を全て計算するのではなく間引きをやってきたわけですが、幾分ヒューリスティックな回避策であったわけです。それに、全ての Multi-Head で同じ間引き方をしていたと…そうなんですか? いやいわれてみれば Head ごとに間引き方を変えるべきですよね…。ともかく、現実にはセルフアテンション行列は疎であるということです。まあ特に自然言語処理では過去の単語たちをべったり注意することもないでしょうね。しかしどのように疎なのかがわからないから間引き方がわからないのですが…読み進めると3ページ目の2段目の最上部では、あるステップから各ステップをどれだけ注意するかの分布
と、一様分布
のKLダイバージェンスを取っていますね。なるほど一様分布から逸脱しているほど特定のステップに着目し、重要な情報を掴んでいる見込みが高いというわけでしょうか。以下の図でも計算してみました。

続きを読もう。しかし逸脱度自体を得るのに かかってしまう、だから逸脱度を近似するというようにあるよ。まず補題1で逸脱度の上下限を示しているね。上下限がこうなるのは上図の式と見比べればわかる。それでこの上限の方を、完全なセルフアテンション行列からではなく、サンプリングした一部の要素だけ計算したセルフアテンション行列から見積もる。
の分布の形にある程度の仮定をおけば、
の行と
の列の組を
組サンプリングすることで見積もれるって。そのことをきちんと示したのが命題1かな。
が正規分布にしたがうとしているのはどれくらい適切なのかわからないけど。まあ確かに分布が一様分布から離れているかって、分布の一番高いところが高かったらそれは離れているし、各行の最大値を見積もるだけなら行列の要素を全て計算しなくてもよさそうだよね。
サンプリングの仕方は追えていませんが、一様分布から離れているかどうかというのは、過去のヒューリスティックな回避策に比べれば積極的に意味のあるアテンションを残そうとしていますね。
セルフアテンションの計算量の問題が片付いたら次はメモリの問題でしたっけ。モデルサイズの問題といってもいいのでしょうか。セルフアテンション時の計算量を間引いても、セルフアテンション層をどんどん積み重ねるならパラメータ数とメモリ使用量は増えるばかりです。
その問題については論文4ページ目の Figure 3 をみるに、セルフアテンション層を抜ける度に Conv1D + MaxPool1D することで系列の長さを半分にしているようにみえるね。あ、この図では Attention Block という薄オレンジの直方体の中にガラス板(?)が4枚浮かんでいるようにみえるけど、これは4つのヘッドのセルフアテンション行列だね。式 (5) をみると Conv1D を適用した後に ELU で活性化している。
では最後はここまで改造した Transformer を用いてどのように推論するのかという問題ですか。1ステップずつ再帰的に読み出していくのでは時間がかかるというより誤差が積み重なっていくのですよね?
それについてはそのまま「1ステップで読み出すようにした」という感じにみえるな。以下にイメージ図を描いたよ。水色が目的変数でピンク色が説明変数(タイムスタンプなど)ね。本文中の例では、向こう7日分を予測するのに、デコーダにここまでの5日分をフィードするみたい。それで予測してほしい箇所はゼロにした状態(いわば「プレースホルダ」)を渡してそこに埋まるものを返してねって感じなんだけど、エンコーダに渡す期間とデコーダに渡す期間が把握できていないから、以下の図は GitHub の Informer の実装をみて描き直すかもしれないかな…。それで損失関数は MSE とあるね。検証したのは全部回帰タスクみたいだし。特に言及がないから、近い未来の誤差も遠い未来の誤差も重さは等しいということなのかな?

検証データと比較手法
ではモデルについては一通り確認したので検証されたデータセットをみてみましょう。「電気」「電気」「天気」といったところでしょうか。
| ETT (Electricity Transformer Temperature) | これは著者らが収集されたデータなのですね。以下に公開されているようです。Electricity Transformer Temperature という言葉が聞き慣れないですが、このデータセットは「変圧器の油温」を予測することを企図したものであるようです。よくわからないのですが、変圧器の油温というのが上昇しすぎると危険であって、変圧器に負荷がかからないように送電するために重要な指標ということなんでしょうか。説明変数には High UseFul Load などが含まれていますがこれは最大実効負荷などと訳すのでしょうか。ともかく、ETT-small-m1, ETT-small-m2 というのが中国のある2つの省の分単位のデータであって2年×365日×24時間×60分=1,051,200点のデータを含むそうです。時間単位になっている ETT-small-h1, ETT-small-h2 なるデータもあるようですね。 |
|---|---|
| ECL (Electricity Consuming Load) | また電気ですが、お馴染みの UCI Machine Learning Repository のデータですね。 UCI Machine Learning Repository: ElectricityLoadDiagrams20112014 Data Set このデータは NeurIPS2018 の Deep State Space Models for Time Series Forecasting や NeurIPS2020 の AST でも利用されていました。ある期間におけるポルトガルの370人の個々の顧客の15分ごとの電力消費量です。 |
| Weather | アメリカの1600地点での1時間毎の気候データでしょうか。論文中のリンクは以下に転記してみましたが、この記事をかいている時点で重すぎてアクセスできる気配がないのですよね…。 |
| ARIMA | ARIMA は ARIMA ですね。ただ ARIMA の参考文献として以下が引用されているのは何故なんでしょうか。 |
|---|---|
| Prophet | Prophet も Prophet です。 |
| LSTMa | LSTMa とは…? これは機械翻訳の論文のようですが、LSTM を普通に利用するのではなく、LSTM の各ステップの特徴を用いてデコードするコンフィギュレーションのことを LSTMa というのでしょうか。間違っていたらごめんなさい。 |
| LSTnet | LSTnet は以下の論文を読んだときに引用されていましたね。絵も描きました。畳込みと再帰のハイブリッドモデルさんでしたね。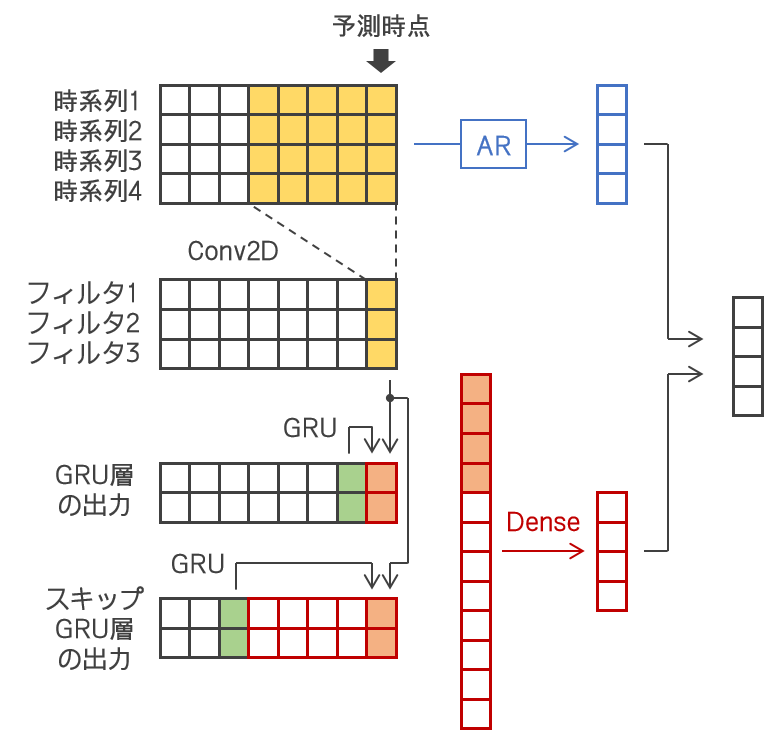 |
| DeepAR | DeepAR も DeepAR です。AST でも DeepAR の敵対的学習を試行されていましたね。ただ DeepAR は後続に Deep State Space Models があったと思いますがそちらは利用できないものなのでしょうか。 |
その結果が Table 1, Table2 ですね。ほとんどのタスクで Informer が最高精度を達成しています…って、通常のセルフアテンションよりも高精度が出ているタスクが多いのですね。Informer はセルフアテンション行列の計算を間引いたのに間引かないよりも性能がよいとはなぜなのでしょう?
取るに足らないアテンションなら最初から要らなかったということだよね。単変量予測の Table 1 で目立つのは ECL データの 48, 168, 336 ステップ先予測で DeepAR が健闘しているね。どうしてなんだろう?
私にいわれましても…。多変量予測の Table 2 もだいたい Informer 眷属の独断場ですがたまに LSTnet さんが健闘していますね。
Table 2 のモデルの中でさ、畳込みも再帰も利用しているのって LSTnet だけだよね。Transformer は特殊な畳込み扱いとして。逆に色々使っている LSTnet が少ししか勝てないのが Transformer の威力なんじゃないのかな。