【下のノートについて】多変量正規分布があったとき、 から
への線形回帰と
から
への線形回帰は一致しないらしいんですが、あまり納得できなかったのでどう説明したら納得できるか考えてみたんですが、やっぱりあまり納得できなかったし、あとグラフに確率密度の等高線を描いた方が一目瞭然だったんじゃないかと思いました。「こう考えれば自明では」というのがあったら教えてください。よろしくお願いします。
gistaeb8a4a5dd292f783c69c28907da96ee
ベイズ統計の理論と方法: ノート2
以下の本を読みます。キャラクターは架空のものです。解釈の誤りは筆者に帰属します。おかしい点がありましたらコメント等でご指摘いただけますと幸いです。

- 作者: 渡辺澄夫
- 出版社/メーカー: コロナ社
- 発売日: 2012/03/01
- メディア: 単行本
- 購入: 1人 クリック: 4回
- この商品を含むブログ (8件) を見る
前回:ノート1 / 次回:まだ
- 前回のノートでは確率と確率密度がごっちゃになっているところがあります。事象
が起きる確率
に対して
は事象
の確率密度関数
に対して
は選択情報量とはよばないと思います。よばないと思いますがよび方に困るので、以下「選択情報量のような量」とよんでいます(自由エネルギーのことなんですが、自由エネルギーって何っていうことばとして)。
- そんな変な呼び方をしなくても「負の対数尤度」などとよべばさしつかえはないですが、個人的にそうよぶとそれって大きいほどどういう意味だっけというのがなんかすぐわかんないので採用しません。

前回読んだ1~10ページの内容をふりかえります。この本はベイズ推測について解説する本であり、ベイズ推測とは何かというのは 1.1 節に定義がありました。つまり、「ベイズ推測する」とは
サンプル  内の各点が独立に従っている分布は、確率モデル
内の各点が独立に従っている分布は、確率モデル  の事後分布
の事後分布  による平均
による平均 ![\mathbb{E}_w \bigl[p(x|w) \bigr] \equiv p(x|X^n)](https://chart.apis.google.com/chart?cht=tx&chl=%20%5Cmathbb%7BE%7D_w%20%5Cbigl%5Bp%28x%7Cw%29%20%5Cbigr%5D%20%5Cequiv%20p%28x%7CX%5En%29) だろうと考える(★)
だろうと考える(★)
ことに他なりません。ここで事後分布 しかし、「~だろうと考える(★)」というだけでは、「じゃあそう考えれば?」という話です。この本で私たちが学ぶのは、「『~だろうと考える(★)』というのは結局どういうことなのか」でしょう。

しかし「よい推測」とは何かという問題があります。私たちは現実に推測を行う場面で真の分布を知り得ないので、真の分布にどれだけ近づけたかを確認することはできません。しかしそれでも、 に拠らない数学的な法則が存在して、推測の「限界」を議論することができるということですが…。1章の続きではその足掛かりとして、「自由エネルギー
」と「汎化損失
」が定義されました。
- 自由エネルギー
は事前分布
と確率モデル
とサンプル
による量で、分配関数
の対数の温度倍のマイナス1倍です。
のとき
は周辺尤度(その確率モデルでその事前分布にしたがうあらゆるパラメータの下でサンプル
の対数のマイナス1倍に等しいです。確率密度を確率のようなものと思えば、
で平均すると)、
- 汎化損失
は真の分布
と予測分布
の交差エントロピーです。しかし、やはり知り得ない
から見積るということですが…。
が観測される事象の選択情報量のような量の全サンプル平均」です。
本のデルタ関数が立った)経験分布と予測分布の交差エントロピーととらえることもできるかもしれません。
右辺第1項と右辺第2項は丁寧にかくとこうかな。
…なるほど、もし仮にその事前分布と確率モデルの下で
え、えっと? ともかく、何が何の変数で、何が確率変数なのかややこしいですね。改めて整理します。10ページの上・中・下3箇所の数式は、それぞれ「確率密度」「選択情報量のような量」「交差エントロピー」にみえて、2ステップ更新されたようにみえるんです。でも、右辺は2ステップなのですけど、左辺は3ステップあったのですね(中から下への更新に、先に で積分して、次に残りの変数で積分するという2ステップの更新が含まれています)。つまり、右辺(上側の表)と左辺(下側の表)でそれぞれ主人公が以下のように交代しています。
| 事前分布で平均した確率モデルの下でサンプル | |
| 事前分布で平均した確率モデルの下でサンプル | |
| 「真の分布」と「事前分布で平均した確率モデル」の交差エントロピー or 真の分布の下でのあらゆるサンプル |
| 予測分布の下で点 | |
| 予測分布の下で点 | |
| 点 | |
| 真の分布の下でのあらゆるサンプル |
…汎化損失と自由エネルギーにある関係が成り立つのはわかりました。11ページは、なぜ確率密度の対数のマイナスをとるのかという話をしていますね。…これ、「確率密度は
まあ確率密度が の形であるかどうかとエネルギーの登場はおいといても、確率
を対数のマイナス1倍をとって
として「選択情報量」というものさしでみると「大きいほどめずらしい、それが起きたと知ったときの価値が高い出来事だ」って何となくわかりやすかったよね。こっちのものさし方が推測のよさを測るのに感覚に合ってそうだ。もちろん確率
のままでも推測の誤差を議論することはできると思うけど…でも、元々よく起きる出来事か、レアな出来事かで確率を1%誤る重大さって違う気がするよね。ある年に名古屋では年間に100日くらい雨が降って、10日くらい雪が降ったらしい。真の値より10日多めに110日雨の予報を出してもたぶんあまり怒られないけど、真の値より10日多めに20日雪の予報を出したらたぶんクレームがくるだろうし天気予報を信用してもらえなくなるよね。
いや、雪の日は実際タイヤチェーンなどさまざまな準備が必要ですから、事象自体が誤りの重大さに関係していてその喩えはあまり適切ではないのでは…まあ雰囲気はわかりますが。ただ、それなら確率の誤差ではなく誤差率をみるということもできると思いますが…。
率って扱いにくいし、誤差が小さければ誤差率は対数差分で近似できるしね。 がゼロに近ければ
だよね。
なんと、確かにそうなりますね。
あと確率密度が の形かってのも、何か物理法則にしたがうデータだったらそうなる見込みがあるからね。その辺は統計力学の話になるけど。
やっぱり物理の話じゃないですか…まあ にさまざまな解釈が与えられるというのはいいです。次節に進みましょう。…事後分布や予測分布を「解析的に計算できない」ことが多い? 「解析的に計算できない」って何ですか? (1.5) 式や (1.8) 式ってそんなに何か困難な要素があるんですか??
「解析的に解けない」っていうと解が既知の演算や関数でかきあらわせないって意味だね。「5次方程式は一般的に解けない」というのは一般の係数の加減乗除べき根で方程式の解をかきあらわすことができないって意味だし。ただここでいう既知の演算や関数が何かはまだわからないかな。まあこの節に「計算できる例」があるってことなんだからそこから推し量ることはできるんじゃない?
そうですね、この節の例を計算してみましょう。 で
ということです。
と
の制約はわかりませんが確率モデルが積分できることは確かですね。このとき、分配関数及び事後分布を計算すると、
これは…ハイパーパラメータ が更新された形になりましたね。
…確率モデル と事前分布
の積が
の形にかける(
は
に依存しない係数)なら
になって事後分布が
になるってことか。逆に事後分布をこの形にしたいなら…やっぱり
と
の積が
の形にかけないといけない。
と
の積の
への依存性はこの形でないといけない。「事前分布を事後分布にする」ことを「ハイパーパラメータ
を更新する」形で達成することは、以下を満たす確率モデルと事前分布を選ぶことと同じように感じる。
「解析的に解ける」というのは結局「パラメータの更新で済む」という意味だったんでしょうか….? もちろん、「パラメータの更新で済む」ような確率モデルと事前分布を選ばなければならないという意味ではないと14ページにありますね。あくまで人間の都合です。…1.3節はさまざまな推測方法ということですが…最尤推測って のベイズ推測なんですか??
2019-05-07 追記
> 一般の場合にも最尤推定値にたつデルタ関数っていうのを示すのはどうやるのかすぐ思いつかない
以下のような感じな気がします。
https://twitter.com/CookieBox26/status/1125552313572020224
> 一般の場合にも最尤推定値にたつデルタ関数っていうのを示すのはどうやるのかすぐ思いつかない
以下のような感じな気がします。
https://twitter.com/CookieBox26/status/1125552313572020224
17ページの (3) にある場合にベイズ推測と最尤推測が同じといえるのかいえないのかといった気になることがかいてありますね…まあいまはとばしますか。18ページからは解析的に解ける場合で数値実験しているようですね。…節変わって23ページに、「確率モデルが仮のものである場合」とありますね。もちろん確率モデルがわかっている場合とわかっていない場合とあるのはわかるんですが、だから何を言いたかったんでしょうか…。
「1000人の試験結果のときと100万人の試験結果のときで推測されるパラメータがずれていてもいい」って感じに読めるね。仮に100万人の試験結果が正規分布を 個混合した分布で上手くフィッティングできても「中学生全体が
個のグループに分けられると結論されたのではない」というのは、
は「100万人の試験結果の解析に有用なパラメータ」に過ぎないってことだね。
じゃあ、中学生全体の試験結果が何個にクラスタリングされるかを研究することはできないってことですか?
やっちゃいけないのは、特に根拠なく混合正規分布を仮定して、100万人の試験結果から推測した でもって「中学生というものは
個のグループに分けられます」と結論付けることだ。「この100万人の中学生は」と付けるなら間違ってはないだろうけどね。本当に「中学生は
個のグループに分けられるのではないか」という仮説を検証したいなら、きっと人数を増やして収束していくかとか確認すべきで、現実にはそこで頓挫するんじゃないかな。
カーネル法入門: ノート2
以下の本を読みます。キャラクターは架空のものです。解釈の誤りは筆者に帰属します。お気付きの点がありましたらコメント等でご指摘いただけますと幸いです。
")
カーネル法入門―正定値カーネルによるデータ解析 (シリーズ 多変量データの統計科学)
- 作者: 福水健次
- 出版社/メーカー: 朝倉書店
- 発売日: 2010/11/01
- メディア: 単行本
- クリック: 19回
- この商品を含むブログ (11件) を見る
以前カーネル法を勉強したときの記事: パターン認識と機械学習 下(第6章:その6〈終〉) - クッキーの日記
 の標本分散共分散行列を固有値分解しなければならないところを、
の標本分散共分散行列を固有値分解しなければならないところを、 は
は  の部分空間
の部分空間  から探せば十分ということに着目して を表現し、最適化問題から を排除してしまうとは、なかなかトリッキーですね…。
から探せば十分ということに着目して を表現し、最適化問題から を排除してしまうとは、なかなかトリッキーですね…。 は無数に出てきちゃうんだよね。そうだな…以下の PRML の 146 ページに Figure 3.4 があるよね。Figure 3.4 の左側の図を例にすると、これはちゃんと
は無数に出てきちゃうんだよね。そうだな…以下の PRML の 146 ページに Figure 3.4 があるよね。Figure 3.4 の左側の図を例にすると、これはちゃんと  が退化していないケースで、誤差2乗和(青い等高線)が最小になる点があるんだよね(青い点)。誤差2乗和はこの青い点を底にしたお椀になってる。でも、 が退化しているとこれみたいなお椀にならない。スノボのハーフパイプみたいにずーっと谷底が続いてたり、最悪まっさらな平面で「全体的に底」って感じになっちゃう。そうなると最小点を選べなくて困る。その解決策として、「じゃあ別のお椀をもってくればいいじゃん」というのが正則化項だ。Figure 3.4 の左側の図の赤い等高線が原点を底にした「L2ノルムのお椀」だね。このお椀を重ね合わせれば最小点が求まるって寸法だね(※)。もちろん、元々の
が退化していないケースで、誤差2乗和(青い等高線)が最小になる点があるんだよね(青い点)。誤差2乗和はこの青い点を底にしたお椀になってる。でも、 が退化しているとこれみたいなお椀にならない。スノボのハーフパイプみたいにずーっと谷底が続いてたり、最悪まっさらな平面で「全体的に底」って感じになっちゃう。そうなると最小点を選べなくて困る。その解決策として、「じゃあ別のお椀をもってくればいいじゃん」というのが正則化項だ。Figure 3.4 の左側の図の赤い等高線が原点を底にした「L2ノルムのお椀」だね。このお椀を重ね合わせれば最小点が求まるって寸法だね(※)。もちろん、元々の  が退化していない場合でも正則化のお椀を重ねていい。Figure 3.4 は誤差2乗和の青いお椀と正則化の赤いお椀を重ねて、重ねてできた新しいお椀の底になるのが
が退化していない場合でも正則化のお椀を重ねていい。Figure 3.4 は誤差2乗和の青いお椀と正則化の赤いお椀を重ねて、重ねてできた新しいお椀の底になるのが  ってことだね。
ってことだね。

 にpolyカーネル
にpolyカーネル  を選んだときよりもrbfカーネル
を選んだときよりもrbfカーネル  を選んだときの方が点の密度が大きいところを通れているといえばいるような。(ノート3があれば)つづく
を選んだときの方が点の密度が大きいところを通れているといえばいるような。(ノート3があれば)つづく
前回: ノート1 / 次回: まだ
前回のあらすじをまとめると、
- データを分析するには(つまり、ある変数とある変数が依存し合っているかを調べたり、それに基づいて回帰したり分類したりするには)、線形な依存性のみを調べるのでは不十分なこともあるので、非線形な依存性も調べたい。
- 言い換えると、データを
なる特徴写像で特徴空間
- しかし、あらゆる高次項を特徴に追加したのでは、組み合わせが爆発してしまい、主成分分析のために標本共分散行列の固有値分解をしたり、回帰分析のためにデータ行列の擬似逆行列を求めたりすることができない。
- が、少なくとも特徴空間における主成分分析は、行列の各成分が
であるような行数と列数がデータサイズの(有限の大きさの)行列の2乗の固有値分解をすることで達成できる。ので、
の値さえ評価できればよいことになる。ここでポイントとなったのは、
- 特徴空間における第1主軸
の形でかける(もしかけない成分があったら、かけない成分をゼロにしてその分かける成分を引き伸ばした方が各データの
- そうすると解くべき最大化問題の中にデータは
の形でしか出てこない。
カーネルトリックというくらいだからね。
しかし、 は
から探せば十分、というのは通常の主成分分析でも成り立つ話ですよね? 通常の主成分分析の言葉でいうと、第1主軸
を求めるのに、
をあらゆる向きの
次元単位ベクトルから探すのではなくて、
でかけるものを探せば十分、ということになりますよね。
あー、元データの次元数 よりデータサイズ
の方が大きければかえって計算量が大きくなってしまいますね…。8ページからは主成分分析からまた変わって、リッジ回帰という例がありますね。リッジ回帰とは、線形モデルを最小2乗フィッティングするのにパラメータベクトルのL2ノルムの2乗に比例する正則化項を付けて、「誤差2乗和を小さくするパラメータベクトルを求めよ。ただし、パラメータベクトルのL2ノルムの2乗は小さく抑えること」といったもののようですね。その解
は…「容易に求められるように」? 何気ない「容易に」が読者を傷つけるのでは?
まあそこまで説明してもらえばわかります。その式の下の、リッジ回帰はどんなときに利用されるかというので、「 が退化していたり」というのは何ですか?
が正則でないというのは、
の階数が
に満たない、さらに言い換えると
の階数が
に満たないって状況だね。そうなっちゃうのは以下のようなときかな。
- データ数
を上回るほど、データの次元
が巨大であるとき。
- データセットが線型従属なとき(例えば、同じ点が重複して含まれているとか)。
| ※ | 厳密には、もし |
なるほど…誤差2乗和のみでは回帰係数が選びきれないときでも選ぶ基準を新たに与えたんですね。原点を底にしたお椀ということは「選べなかったら原点になるべく近い解にしといて」って感じですよね…?
そうだね。ちなみに、L2ノルムのお椀は Figure 3.4 の左側の赤い等高線のように丸いけど、L1ノルムのお椀はその右側のようにひし形をしてるね。お椀っていうかひっくり返した四角錐だね。だから、L1ノルムで正則化するラッソ回帰では一部の成分がゼロになるような解が求まりやすい。この図でも の点が解になってるね。
じゃあラッソ回帰は「なるべく平面 に貼り付く解にしといて」って感じですかね。…まあラッソ回帰は置いておいて、今回はリッジ回帰を特徴空間でやりたいわけです。特徴空間でのリッジ回帰の目的関数は式 (1.9) ですね。また特徴空間
での内積とノルムが出てきていますね…。
データ空間でやっていた「 の各成分を回帰係数
で足し合わせてそれを予測値としようとする」というのは、特徴空間
でやろうとすると「
とベクトル
との内積をとってそれを予測値をしようとする」ということだからね。
しかし というベクトルはいま得体の知れないもので、カーネルPCAのときは最終的に
は排除されたのですよね。リッジ回帰ではどうなるのでしょう。リッジ回帰でも解は
の形でかけるとありますね。
もし に直交補空間の成分
があったらそれを丸々削った方が正則化項の
が抑えられるからね。
全くですね。ということは…今回もまた最小化したい式の中にデータは の形でしか出てきませんね。
は出てきません。
最適化問題中の を意地でも
の形にするために、
から
を絞り出したって考えればそんなに降って湧いてもないんじゃないかな。
そもそも非線形な依存性を調べたくて などという特徴写像を持ち出したのですから、どのような
が可能なのかが肝心な気がしますが…。ところで今回カーネルリッジ回帰を学びましたが、python の scikit-learn でカーネルリッジ回帰ができるようなので実行してみます。iris データの全品種ごちゃ混ぜで、がく片の長さからがく片の幅を予測するという何がしたいのかわからない例ですが…カーネル関数
には色々なものが指定できるし、自分で実装したものを渡すこともできそうです。組み込みのものを利用するときはおそらく以下の pairwise.kernel_metrics にあるものが指定できると思います。以下のスクリプトではいじっていませんが、パラメータも変更できます。
スクリプト
import numpy as np from sklearn.kernel_ridge import KernelRidge from sklearn.datasets import load_iris %matplotlib inline import matplotlib.pyplot as plt from pylab import rcParams rcParams['figure.figsize'] = 8, 6 rcParams['font.size'] = 16 iris = load_iris() #x = np.array(iris['data'][:,0][iris['target']==0]) # setosa の sepal length (cm) #y = np.array(iris['data'][:,1][iris['target']==0]) # setosa の sepal width (cm) x = np.array(iris['data'][:,0]) # sepal length (cm) y = np.array(iris['data'][:,1]) # sepal width (cm) print(x.shape) print(y.shape) x = x.reshape(-1, 1) y = y.reshape(-1, 1) print(x.shape) print(y.shape) # ----- オリジナル ----- plt.scatter(x, y, label='original') # ----- linearカーネル ----- kr = KernelRidge(kernel='linear') kr.fit(x, y) plt.scatter(x, kr.predict(x), label='predict(linear)') # ----- polyカーネル ----- kr = KernelRidge(kernel='poly') kr.fit(x, y) plt.scatter(x, kr.predict(x), label='predict(poly)') # ----- rbfカーネル ----- kr = KernelRidge(kernel='rbf') kr.fit(x, y) plt.scatter(x, kr.predict(x), label='predict(rbf)') plt.legend() plt.show()
(150,) (150,) (150, 1) (150, 1)
カーネル法入門: ノート1
以下の本を読みます。キャラクターは架空のものです。解釈の誤りは筆者に帰属します。お気付きの点がありましたらコメント等でご指摘いただけますと幸いです。
")
以前カーネル法を勉強したときの記事: パターン認識と機械学習 下(第6章:その6〈終〉) - クッキーの日記
次回: まだ
おそらく1章の2~3ページで挙げられているのが最も簡単な例だね。「データの線形性しか扱わない」というのは、「データの空間のどこかにデータを仕切るような超平面を置いて、その超平面から表側に垂直に離れるほどプラスのスコア、裏側に垂直に離れるほどマイナスのスコア、のようなスコア付けでもってデータを分類したり回帰したりしようとする」ということだろう。でもまっすぐな仕切りで仕切れないのが図1.1の例だね。「高次モーメントを扱う」というのは「2つの変数 に対して
の
次かつ
の
次のモーメントからわかる依存関係を捉える」って感じなんだろうか。図1.2は
の方を2乗しないと相関係数が小さくなる例だね。相関係数がゼロであることは独立であることを意味しないというのは有名だね(ウィキペディアの「相関係数」の頁の絵)。
そこまでごり押されなくても「線形の解析では不十分」であることに異存はないですよ…。確かに、図1.1で分類しようとしたり、図1.2で がどうなると
がどうなるかという関係を見出したりするには線形関数では足りませんね…もっと柔軟なモデルでなければ…解決策を思い付きました。決定木を使いましょう。
解決できるのはできると思うけど、本のタイトルが「決定木入門」になっちゃうかな。
図1.1の方は図の2次元空間の上に という「その場所では + か ○ のどちらか」という関数を見つけたいのですよね。それを
とすることで
を線形関数で足りるようにしたんですね。図1.2の方は、
と
の相関を最大化するのに、
とすることで
を線形関数で足りるようにしたという感じでしょうか。…なんというか、これらをみるとカーネル法とはむしろ「何が何でも線形関数で解く。線形関数で解けるようにデータの方が動くべき」というものにみえますね。ニューラルネットワークの方が人としての器が大きいのではないですか? あちらは「データはそのままでどんな関数でも表現する」でしょう?
はあ。まあ何にせよカーネル法ではデータを都合よく動かさなければならないということですよね。しかし4ページをみると、あらゆる高次のモーメントを考慮するには組合せが爆発してしまうようですが。前途多難では?
にもかかわらず効率的に高次モーメントを抽出できますよというのがカーネル法の売りだからね。
どうやってそんなことを…まあそれがこれからの話題ですか。1.1.2節に移りましょう。データの空間が で、それを移す実ベクトル空間が
ですか。図1.1や図1.2の左側が
、右側が
ということですよね? …実ベクトル空間というのは?
それは結局、ベクトルを集めた集合ではないんですか? 3次元実数ベクトルが入っている は結局
ということではないんですか?
どちらかというと実ベクトル空間の条件を満たす集合があったとき、その元をベクトルというかな。あと、3次元実数ベクトルを含む でも、
内のある平面だけとかある直線だけとかの実ベクトル空間はありうるね。
データ分析では点がどのように密集(分布)しているかに興味があるからね。「ここに仕切りを入れられそうだ」「これが主成分だ」とかいうには点どうしの近さが決まっていないと始まらない。
それって決めないと決まらないものですか? 内積って のように授業で習った気がするのですけど。
対称行列 について、
は内積になるからね。
それはおいおいかな。そこがカーネル法の基本原理だからね。5ページからは実用例みたいな話が始まってるね。
カーネル主成分分析、ですか。通常の主成分分析もわからないのですが…python の scikit-learn でも使えるようなのでまずは実行してみますか。
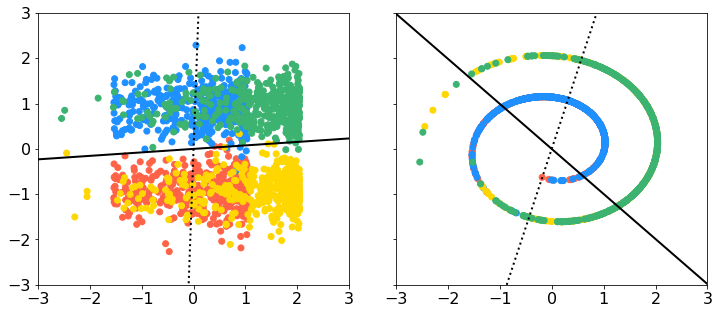
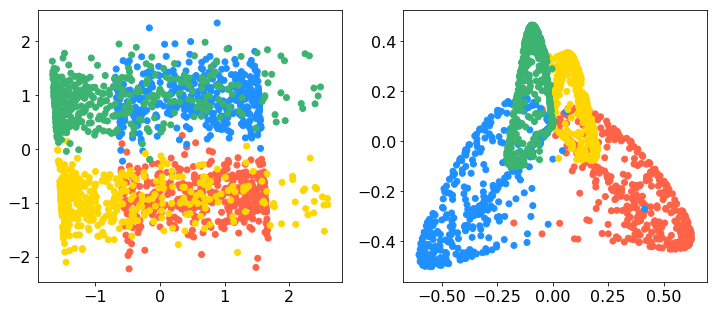
データはそうですね、非線形性があるものがいいのですよね。以下にスイスロールのデータがあったのでこれをお借りすることにします。3次元で、y軸に垂直に切ると渦巻きになっているようなデータですね。上のデータに sklearn.decomposition の PCA と KernelPCA を適用したのが下図です(スクリプトは記事の最下部)。左上が元のデータをxy平面に落とした図、右上が元のデータをxz平面に落とした図ですね。左下が通常の主成分分析の第1主成分-第2主成分、右下がカーネル主成分分析の第1主成分-第2主成分です。上段の実線は通常の主成分分析の第1主軸の方向、点線が第2主軸の方向ですね。データ点は上のリンク先の gif と同じ4色の塗分けをしています。よくみると、スイスロールはこの4つのクラスタに切り分けられるのかもしれませんね。色が同じ部分がやや密集しているようです。なるほど、ありがとうございます。6ページからは主成分分析を今度は特徴空間 で実行しようとしているんですね。先ほどは各データ
を
方向に正射影した
たちの分散を最大化しようとしていましたが、今度は
なるものの分散を最大化しようとしていますね。
の下で。
内積 とノルム
さえ決まっている空間であれば、主成分分析はできるということだね。
それで、解は の形で探せば十分?? え、えっと、なぜこの形で十分かもわからないですが、
とは何なんですか? 先ほど通常の主成分分析でデータの分散が最大となる向きの単位ベクトル
を探したように、
も
内の単位ベクトルというわけではないんですか? これ、ベクトルなんですか??
そういうことですか…ではイメージを捨てて、内積で考えるようにしましょう。…すみません、部分空間と直交補空間とは何でしょう。
うーん、よく知っているベクトルのイメージに戻っちゃうけど、 というベクトル空間を考えて、この空間の中のある平面だけみると、この平面は和とスカラー倍で閉じているから
の部分空間だ。直交補空間というのは、その平面に垂直な直線の中で閉じている空間だね。
とかけるベクトルたちの空間と
とかけるベクトルたちの空間って感じかな。それでいま考えている話に戻ると、
という特徴空間の中には
の和やスカラー倍ではつくれない「ベクトル」がある。
の和やスカラー倍でつくれない、というのは、
たちがつくる部分空間に射影したベクトルを差し引いてもゼロでないベクトルが残っているってことだね。ただ、もし
というベクトルがそのようなゼロでないベクトルを含むようなものであったとしても、その差し引き残ったベクトルってあってもなくても
との内積の値に影響しない。いま「データの分散が最大となる向き」
を探したいわけだけど、もし
の
がゼロでなかったとしよう。このとき
だけど、
とすれば、
への射影の方が
への射影よりデータの分散が単純に
倍大きくなるんだよね。いま
のノルムは1という制約があるんだから、
との内積の値に影響しない成分に割り振ってる余裕はないってとこかな。
だから たちがつくる部分空間内で探せば十分、つまり、(1.6) 式の形で探せば十分ということですか。次元がよくわからない、というか次元という概念があるのかどうかもよくわからないベクトル空間でも、有限個の係数を探せばよいということになるんですね。そうなると、さっきとそっくりな解き方ができるんですね。しかし、先ほどと違って
の
というのはもはや「ベクトルの向き」を意味しませんね。そして、7ページの下部の式のように第
主成分まで求まるんですね。これがカーネルPCA…。
スクリプト
import numpy as np import pandas as pd df = pd.read_csv('swissroll.dat', sep='\s+', header=None) df = df.apply(lambda x: x / x.std(), axis=0) # 標準化 df[1] = df[1] - df[1].mean() # y軸だけ中央がゼロでないのでシフト print(df.head()) c = np.array(['tomato', 'dodgerblue', 'gold', 'mediumseagreen']).repeat(400) # 4色に色分け # PCA from sklearn.decomposition import PCA pca = PCA() pca.fit(df) df_pca = pca.transform(df) # KernelPCA from sklearn.decomposition import KernelPCA kpca = KernelPCA(kernel='rbf', gamma=1.5) kpca.fit(df) df_kpca = kpca.transform(df) # プロット %matplotlib inline import matplotlib.pyplot as plt from pylab import rcParams rcParams['font.size'] = 16 x = np.array([-10, 10]) fig, axes = plt.subplots(ncols=2, figsize=(12, 5), sharex=True, sharey=True) axes[0].scatter(df.iloc[:,0], df.iloc[:,1], c=c) axes[0].plot(x, x * pca.components_[0][1] / pca.components_[0][0], c='black', linestyle='solid', linewidth=2) # 第1主成分 axes[0].plot(x, x * pca.components_[1][1] / pca.components_[1][0], c='black', linestyle='dotted', linewidth=2) # 第2主成分 axes[0].set_xlim([-3, 3]) axes[0].set_ylim([-3, 3]) axes[1].scatter(df.iloc[:,0], df.iloc[:,2], c=c) axes[1].plot(x, x * pca.components_[0][2] / pca.components_[0][0], c='black', linestyle='solid', linewidth=2) # 第1主成分 axes[1].plot(x, x * pca.components_[1][2] / pca.components_[1][0], c='black', linestyle='dotted', linewidth=2) # 第2主成分 plt.subplots_adjust(wspace=0.15) plt.show() fig, (axL, axR) = plt.subplots(ncols=2, figsize=(12, 5)) axL.scatter(df_pca[:,0], df_pca[:,1], c=c) axR.scatter(df_kpca[:,0], df_kpca[:,1], c=c) plt.show()
機械学習のための特徴量エンジニアリング: ノート2
以下の本を読みます。キャラクターは架空のものです。解釈の誤りは筆者に帰属します。お気付きの点がありましたらコメント等でご指摘いただけますと幸いです。
")
機械学習のための特徴量エンジニアリング ―その原理とPythonによる実践 (オライリー・ジャパン)
- 作者: Alice Zheng,Amanda Casari,株式会社ホクソエム
- 出版社/メーカー: オライリージャパン
- 発売日: 2019/02/23
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
正誤表リンク: https://www.oreilly.co.jp/books/9784873118680/
 のテーブルに合計 のカウントを加えるなら、この手続きによるアイテム
のテーブルに合計 のカウントを加えるなら、この手続きによるアイテム  のカウントの推定値は
のカウントの推定値は  以上の確率で誤差
以上の確率で誤差  以内になるらしい。理由は簡単だね。1つの行にのみ着目すると、アイテム が入っているマスに他のアイテムのカウントがどれだけ混入するか(誤差)の期待値は
以内になるらしい。理由は簡単だね。1つの行にのみ着目すると、アイテム が入っているマスに他のアイテムのカウントがどれだけ混入するか(誤差)の期待値は  だ。となると、マルコフの不等式より、誤差が
だ。となると、マルコフの不等式より、誤差が  以上になる確率は
以上になる確率は  以下だ。これが
以下だ。これが  行あるから、全ての行で誤差が 以上になる確率は
行あるから、全ての行で誤差が 以上になる確率は  になる。
になる。 
 の制約のもとで
の制約のもとで  の長さを最大にするには、
の長さを最大にするには、 は の最大の特異値によって引き延ばされる向きを向いていなければなりませんね。…せっかく次元削減できたのに、110~111ページで計算コストが高いだの色々言われていますね…。111ページに、この手法の実用場面として「時系列の異常検出」と言及されていますね。112ページで、ZCA は「相関関係を取り除くことができ」「画像のより面白い構造を見つけ出すことに集中」ってどんな画像になるんでしょう?つづきは後で
は の最大の特異値によって引き延ばされる向きを向いていなければなりませんね。…せっかく次元削減できたのに、110~111ページで計算コストが高いだの色々言われていますね…。111ページに、この手法の実用場面として「時系列の異常検出」と言及されていますね。112ページで、ZCA は「相関関係を取り除くことができ」「画像のより面白い構造を見つけ出すことに集中」ってどんな画像になるんでしょう?つづきは後で
前回: ノート1 / 次回: まだ
5章は「カテゴリ変数の取り扱い」というタイトルですね。以前参加した Kaggle のコンペティションでも「職業」というカテゴリ特徴があって「会社役員、会社員、…」といったカテゴリ値があった気がします。83ページの Effect コーディングというのは初めて聞きました。これ、サンフランシスコのデータの予測値が 、ニューヨークのデータの予測値が
、シアトルのデータの予測値が
になるということですか。だから切片
が全体平均になると。
正確にいうと、「サンフランシスコのデータとニューヨークのデータとシアトルのデータを等しい重みで平均した値」だと思うな。元データ中にカテゴリ値の偏りがあったら はそのデータ全体の平均ということにはならないはず。
84ページの最下部の「参照カテゴリに対する各カテゴリの相対的な影響をエンコードすることは」という箇所を読んでイメージが湧きました。ダミーコーディングにおける は、ニューヨークを原点にとったときの各カテゴリ値の特徴量なんですね。確かに、「なぜニューヨークが原点なのか」という感じはしますね。決定木のような原点の場所がどこかということは何も関係ないモデルでは関係なさそうですが。5.2.1節の特徴量ハッシングというのは、ランダムにカテゴリ値をまとめてしまうということですよね…例 5-3 のコードでは、おそらくレビュー文章か何かの単語列(word_list)を、m 次元の数値ベクトルに変換していますね。単語毎にベクトルのどの成分をインクリメントするかは、その単語の生のハッシュ値を m で割った余りで決めています。例 5-4 の方は似ていますが、インクリメントするかデクリメントするかもまたハッシュ値で決めています。こうすると大きなバイアスが発生しない?? どういうことでしょう。
ちょっと例を考えてみようか。元々単語のユニーク数が9個だったとする。この時点でじゅうぶん少ないけどあくまで例だからね。いま手元の2つの文章を、どの単語IDが何回現れるかで9次元にエンコードしたとする。仮に以下のような感じになったとする。
- 文章X:
- 文章Y:
- 文章X:
- 文章Y:
- 文章X:
- 文章Y:
確かに bag-of-words ではコサイン類似度などで類似度が測られるのでしたっけ。次元を圧縮したいからといって内積が保たれない表現にしてしまっては台無しですね。元々の bag-of-words は「意味が近い文章どうしは距離が近くなっている」がゆえに文章を表現する特徴量たりえたのですから。意味が近くない文章どうしでなくても距離が近い表現など、適切な特徴量とはいえません。5.2.2 節は、カテゴリ毎の何かの最小値や最大値などでもよいのでしょうかね。94ページの最小カウントスケッチというのは? これはレアではないカテゴリも含めて 種類の
値へのマッピングを用意するということでしょうか。そして最小値を正式に採用する? うーん、やり方はわかるんですが、ハッシュ関数を
個にすると結局何がよかったのかとかなぜ最大値などではなく最小値をとるのかとかよくわかりません…。
Count-Min Sketch の原論文の [Cormode & Muthukrishnan, 2005] というのはおそらく以下の記事にリンクがあるものだね。
上の文書の3ページに書いてある手続きは本の94ページと全く一緒だ(絵も似ているね)。そうか、「余計なアイテムのカウントが一番小さいマスを選びたいのだ」という気持ちであれば最小値を選ばなければなりませんね。統計量が何かのカウントであるとは限らないと思いますが。
95ページの一番下の段落はどういう意味でしょうか。「任意のデータ点の有無によって統計量の分布がほぼ変わらない」?
音楽を推薦するモデルをつくるのに、アーティストを特徴量にしたいけど、アーティストはきっと多いからそのままカテゴリ値として扱いたくない。だから、「レディー・ガガ」というカテゴリ値の変わりに「レディー・ガガの曲の再生回数の全ユーザ合計」のような連続値にしたい。けど、1人だけ異様にレディー・ガガの曲を再生しているユーザがいたらよくない。任意のユーザを抜いたとしても、あらゆるアーティストの再生回数合計の分布が変わらない必要がある、ということかな…いや、任意のアーティストを抜いても分布が変わらない、かもしれないかな…もしレディー・ガガだけ再生回数が断トツで多かったら、どのユーザにもレディー・ガガばかり推薦されることになっちゃいそうだし…。
そんなに再生回数が多かったらもう万人にレディー・ガガを推薦しておけばよくないですか?
個々のユーザの嗜好を予測しようとして??
6章に入りますね。 特異値分解ですか…以前に特異スペクトル変換法で扱いましたね。
式 6-6 から式 6-7 はこうですね。以下に ZCA をやっている記事があったよ。一番下の方に画像があるね。