以下の本を読みます。キャラクターは架空のものです。解釈の誤りは筆者に帰属します。お気付きの点がありましたらコメント等でご指摘いただけますと幸いです。
")


おそらく1章の2~3ページで挙げられているのが最も簡単な例だね。「データの線形性しか扱わない」というのは、「データの空間のどこかにデータを仕切るような超平面を置いて、その超平面から表側に垂直に離れるほどプラスのスコア、裏側に垂直に離れるほどマイナスのスコア、のようなスコア付けでもってデータを分類したり回帰したりしようとする」ということだろう。でもまっすぐな仕切りで仕切れないのが図1.1の例だね。「高次モーメントを扱う」というのは「2つの変数 に対して
の
次かつ
の
次のモーメントからわかる依存関係を捉える」って感じなんだろうか。図1.2は
の方を2乗しないと相関係数が小さくなる例だね。相関係数がゼロであることは独立であることを意味しないというのは有名だね(ウィキペディアの「相関係数」の頁の絵)。
そこまでごり押されなくても「線形の解析では不十分」であることに異存はないですよ…。確かに、図1.1で分類しようとしたり、図1.2で がどうなると
がどうなるかという関係を見出したりするには線形関数では足りませんね…もっと柔軟なモデルでなければ…解決策を思い付きました。決定木を使いましょう。
解決できるのはできると思うけど、本のタイトルが「決定木入門」になっちゃうかな。
図1.1の方は図の2次元空間の上に という「その場所では + か ○ のどちらか」という関数を見つけたいのですよね。それを
とすることで
を線形関数で足りるようにしたんですね。図1.2の方は、
と
の相関を最大化するのに、
とすることで
を線形関数で足りるようにしたという感じでしょうか。…なんというか、これらをみるとカーネル法とはむしろ「何が何でも線形関数で解く。線形関数で解けるようにデータの方が動くべき」というものにみえますね。ニューラルネットワークの方が人としての器が大きいのではないですか? あちらは「データはそのままでどんな関数でも表現する」でしょう?
はあ。まあ何にせよカーネル法ではデータを都合よく動かさなければならないということですよね。しかし4ページをみると、あらゆる高次のモーメントを考慮するには組合せが爆発してしまうようですが。前途多難では?
にもかかわらず効率的に高次モーメントを抽出できますよというのがカーネル法の売りだからね。
どうやってそんなことを…まあそれがこれからの話題ですか。1.1.2節に移りましょう。データの空間が で、それを移す実ベクトル空間が
ですか。図1.1や図1.2の左側が
、右側が
ということですよね? …実ベクトル空間というのは?
それは結局、ベクトルを集めた集合ではないんですか? 3次元実数ベクトルが入っている は結局
ということではないんですか?
どちらかというと実ベクトル空間の条件を満たす集合があったとき、その元をベクトルというかな。あと、3次元実数ベクトルを含む でも、
内のある平面だけとかある直線だけとかの実ベクトル空間はありうるね。
データ分析では点がどのように密集(分布)しているかに興味があるからね。「ここに仕切りを入れられそうだ」「これが主成分だ」とかいうには点どうしの近さが決まっていないと始まらない。
それって決めないと決まらないものですか? 内積って のように授業で習った気がするのですけど。
対称行列 について、
は内積になるからね。
それはおいおいかな。そこがカーネル法の基本原理だからね。5ページからは実用例みたいな話が始まってるね。
カーネル主成分分析、ですか。通常の主成分分析もわからないのですが…python の scikit-learn でも使えるようなのでまずは実行してみますか。
データはそうですね、非線形性があるものがいいのですよね。以下にスイスロールのデータがあったのでこれをお借りすることにします。3次元で、y軸に垂直に切ると渦巻きになっているようなデータですね。上のデータに sklearn.decomposition の PCA と KernelPCA を適用したのが下図です(スクリプトは記事の最下部)。左上が元のデータをxy平面に落とした図、右上が元のデータをxz平面に落とした図ですね。左下が通常の主成分分析の第1主成分-第2主成分、右下がカーネル主成分分析の第1主成分-第2主成分です。上段の実線は通常の主成分分析の第1主軸の方向、点線が第2主軸の方向ですね。データ点は上のリンク先の gif と同じ4色の塗分けをしています。よくみると、スイスロールはこの4つのクラスタに切り分けられるのかもしれませんね。色が同じ部分がやや密集しているようです。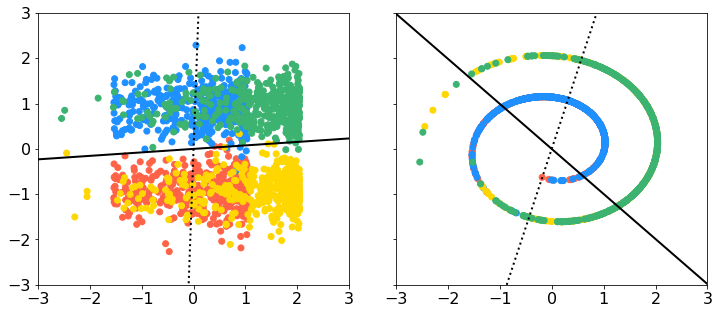
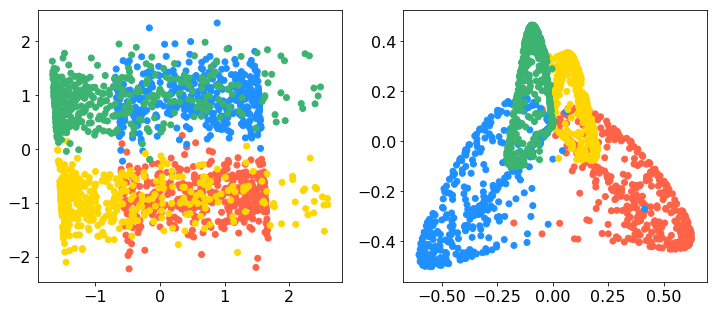
なるほど、ありがとうございます。6ページからは主成分分析を今度は特徴空間 で実行しようとしているんですね。先ほどは各データ
を
方向に正射影した
たちの分散を最大化しようとしていましたが、今度は
なるものの分散を最大化しようとしていますね。
の下で。
内積 とノルム
さえ決まっている空間であれば、主成分分析はできるということだね。
それで、解は の形で探せば十分?? え、えっと、なぜこの形で十分かもわからないですが、
とは何なんですか? 先ほど通常の主成分分析でデータの分散が最大となる向きの単位ベクトル
を探したように、
も
内の単位ベクトルというわけではないんですか? これ、ベクトルなんですか??
そういうことですか…ではイメージを捨てて、内積で考えるようにしましょう。…すみません、部分空間と直交補空間とは何でしょう。
うーん、よく知っているベクトルのイメージに戻っちゃうけど、 というベクトル空間を考えて、この空間の中のある平面だけみると、この平面は和とスカラー倍で閉じているから
の部分空間だ。直交補空間というのは、その平面に垂直な直線の中で閉じている空間だね。
とかけるベクトルたちの空間と
とかけるベクトルたちの空間って感じかな。それでいま考えている話に戻ると、
という特徴空間の中には
の和やスカラー倍ではつくれない「ベクトル」がある。
の和やスカラー倍でつくれない、というのは、
たちがつくる部分空間に射影したベクトルを差し引いてもゼロでないベクトルが残っているってことだね。ただ、もし
というベクトルがそのようなゼロでないベクトルを含むようなものであったとしても、その差し引き残ったベクトルってあってもなくても
との内積の値に影響しない。いま「データの分散が最大となる向き」
を探したいわけだけど、もし
の
がゼロでなかったとしよう。このとき
だけど、
とすれば、
への射影の方が
への射影よりデータの分散が単純に
倍大きくなるんだよね。いま
のノルムは1という制約があるんだから、
との内積の値に影響しない成分に割り振ってる余裕はないってとこかな。
だから たちがつくる部分空間内で探せば十分、つまり、(1.6) 式の形で探せば十分ということですか。次元がよくわからない、というか次元という概念があるのかどうかもよくわからないベクトル空間でも、有限個の係数を探せばよいということになるんですね。そうなると、さっきとそっくりな解き方ができるんですね。しかし、先ほどと違って
の
というのはもはや「ベクトルの向き」を意味しませんね。そして、7ページの下部の式のように第
主成分まで求まるんですね。これがカーネルPCA…。
スクリプト
import numpy as np import pandas as pd df = pd.read_csv('swissroll.dat', sep='\s+', header=None) df = df.apply(lambda x: x / x.std(), axis=0) # 標準化 df[1] = df[1] - df[1].mean() # y軸だけ中央がゼロでないのでシフト print(df.head()) c = np.array(['tomato', 'dodgerblue', 'gold', 'mediumseagreen']).repeat(400) # 4色に色分け # PCA from sklearn.decomposition import PCA pca = PCA() pca.fit(df) df_pca = pca.transform(df) # KernelPCA from sklearn.decomposition import KernelPCA kpca = KernelPCA(kernel='rbf', gamma=1.5) kpca.fit(df) df_kpca = kpca.transform(df) # プロット %matplotlib inline import matplotlib.pyplot as plt from pylab import rcParams rcParams['font.size'] = 16 x = np.array([-10, 10]) fig, axes = plt.subplots(ncols=2, figsize=(12, 5), sharex=True, sharey=True) axes[0].scatter(df.iloc[:,0], df.iloc[:,1], c=c) axes[0].plot(x, x * pca.components_[0][1] / pca.components_[0][0], c='black', linestyle='solid', linewidth=2) # 第1主成分 axes[0].plot(x, x * pca.components_[1][1] / pca.components_[1][0], c='black', linestyle='dotted', linewidth=2) # 第2主成分 axes[0].set_xlim([-3, 3]) axes[0].set_ylim([-3, 3]) axes[1].scatter(df.iloc[:,0], df.iloc[:,2], c=c) axes[1].plot(x, x * pca.components_[0][2] / pca.components_[0][0], c='black', linestyle='solid', linewidth=2) # 第1主成分 axes[1].plot(x, x * pca.components_[1][2] / pca.components_[1][0], c='black', linestyle='dotted', linewidth=2) # 第2主成分 plt.subplots_adjust(wspace=0.15) plt.show() fig, (axL, axR) = plt.subplots(ncols=2, figsize=(12, 5)) axL.scatter(df_pca[:,0], df_pca[:,1], c=c) axR.scatter(df_kpca[:,0], df_kpca[:,1], c=c) plt.show()