お気付きの点がありましたらご指摘いただけますと幸いです。
まとめ
- スラツキーの定理は便利である。
- 分布収束の収束先が連続分布であるであるならば、分布関数は一様収束する。
|
 統計量の漸近分布(+ α )
統計量の漸近分布(+ α )
統計量とは以下のような、確率変数の関数になっているような確率変数でしたよね。分母の  はいわゆる不偏分散です。母分布の分散
はいわゆる不偏分散です。母分布の分散  ではないことに留意してください。
ではないことに留意してください。
定義〈 統計量(※) 〉 
をそれぞれ独立に同一の分布(平均

)にしたがう確率変数とする。このとき、以下の

を
統計量という。

※ 例えば
現代数理統計学(竹村)では明示的に「
正規分布からの無作為標本(中略)を t 統計量という」とあるので
正規分布からのサンプルのときに t 統計量というのだという感じにみえます。他方、逆に
Wikipedia では t 統計量を単に何らかのパラメータの推
定量とその推
定量の
標準偏差で構成されるものと定義しています。「独立同一分布にしたがうサンプルから分布の平均を推定する」という文脈に限っていません。上にかいた定義は [参考文献 1] の定義がこれだろうかと思ってかいたものですが、よく読むと「独立同一分布にしたがうサンプルから分布の平均を推定する」という文脈のときのみ t 統計量というとはどこにもかいていない気がするので文脈を制限しすぎかもしれません。何にせよ、t 統計量の話をするときは相手と定義を確認してください。
特に

がしたがう「同一の分布」が
正規分布 
であるとき、
は自由度

の
分布にしたがうのでした [関連記事 イ]。
統計量は母分布の分散を使用しないので、母分散がわからないときの母平均の値の存在範囲に関する仮説の検定などに用いられますね。つまり、「もし母平均が

であるならば、
はある
分布にしたがうので、
の値がその分布の真ん中付近からあまりに外れていたら
であるか疑わしい」という論法ですね。
では、「同一の分布」が正規分布ではない場合はどうだろう。
正規分布ではない場合ですか? そういわれましても、[関連記事 イ] で 統計量がしたがう分布を導出したときは全体的に母分布が正規分布であることを利用していましたし、分布について何もわからなかったら同じ要領でアプローチすることはできませんね……。
うん。だから、 がとても大きいときを考えてみよう。「 が大きいときは正規分布に近づく」というような定理があったよね?
がとても大きいときを考えてみよう。「 が大きいときは正規分布に近づく」というような定理があったよね?
「 が大きいときは正規分布に近づく」……中心極限定理ですね。
定理〈 中心極限定理 〉 をそれぞれ独立に同一の分布(平均
,分散

)にしたがう確率変数とする。このとき、

は

に分布収束する。
なるほど、この
は
統計量の分子にあたる部分です。
中心極限定理によれば、母分布の分散が有限でさえあれば、その部分は
正規分布に収束していくというわけですね。しかし、分母の

も確率変数ですから、
統計量全体としてどのような分布にしたがうかは依然としてわかりません。
そうだね。ここで、いまは  であるということしよう。それで、後々の都合上、以下の2つの定理をつかって、 が何にどんな収束をするかを考えてみてほしい。
であるということしよう。それで、後々の都合上、以下の2つの定理をつかって、 が何にどんな収束をするかを考えてみてほしい。
定理〈 大数の弱法則(※) 〉 をそれぞれ独立に同一の分布(平均

,分散
)にしたがう確率変数とする。このとき、

は

に確率収束する。
※
がなくても成り立ちますがこの条件込みで弱法則としてチェビシェフの不等式で証明することが多いと思います(例.
清水本)。ただ後から気付いたのですが、[参考文献 1] の15ページではこの条件がないものを
大数の弱法則とよんでいました。証明はそのページをみてください。
定理〈 連続写像定理(確率収束版) 〉 
を

であるような

上の任意の点で連続な関数であるとする。このとき、以下が成り立つ。

とするのですか? そして誘導が強い……まずは [関連記事 イ] と同様に を展開しましょう。

いま、
大数の弱法則より

であり、また、

〈母分布の2乗平均〉

です。よって、
連続写像定理も用いて、

です。これを確率収束の定義に差し戻してかくと以下の

ですが、
が成り立つならば

も成り立つとわかります。


つまり、
は

に確率収束します。であれば
連続写像定理より、
は

に確率収束しますね。
ここまでをまとめると以下です。
- 独立に同一の分布(平均
 ,分散 )にしたがう に対する 統計量について以下のことがいえる。
,分散 )にしたがう に対する 統計量について以下のことがいえる。
- 分子の
 は に分布収束する。
は に分布収束する。
- 分母の は に確率収束する。
……「分子はこう」「分母はこう」とわかりましたが、だから何なのでしょうか。いま分子と分母が独立であるのかもわかりませんし(母分布が
正規分布の場合は独立であることが示せましたが [関連記事 イ] )。やはり全体としての確率変数がどうふるまうかわからないと思うのですが。
ここまできたら以下の補題を適用することができるよ。
定理〈 スラツキーの定理(除算版) 〉 
が

に分布収束し、

が

(ゼロでない定数)に分布収束するとする。このとき、

は

に分布収束する。
はあ……うーん、あの、基礎的な統計学で信頼区間を求めたり、統計的仮説検定をしたりするときは、「この統計量はこの分布にしたがう」がきちんと求まっていましたよね? 対していまわかっているのは、「この統計量はこの分布に『分布収束する』」です。もちろん分布収束するのであれば観測をたくさん重ねていけばその分布に近づきはするでしょうが……しかし、確か分布収束の定義は「分布関数の『各点』が収束すればよい」といったものでしたよね? それだと、観測をある程度たくさん重ねたとき、統計量の分布が収束先の分布に近い形をしている保証はないのではないですか? 各点収束だったら、「こちらのエリアではもう収束先の分布に近いですが、あちらのエリアはまだまだ近くないですね」ということもあり得るでしょう? そのような状況かもしれないのに信頼区間を議論するのは乱暴なのでは?
実際そういう心配はあるかもね。ただ、ここまでの例については一応、分布関数は一様収束しているけどね。
収束先が連続分布であるときの分布収束
連続分布なら以下が成り立つので示してみよう( [関連記事 1] の12ページ)。
補題〈 収束先が連続分布であるときの分布収束 〉 
次元確率変数
は分布関数が連続であるような
に分布収束するとする。このとき、

が成り立つ。
以下のように示せますね……確かに連続分布であれば一様収束します(2022-11-14 追記: 以下の手書きノートでは1次元の場合も2次元の場合も「N'=* をとって、k=* とすれば、」とありますが、N' は k に依存するので「k=* として、N'=* をとれば、」が正しいです)。


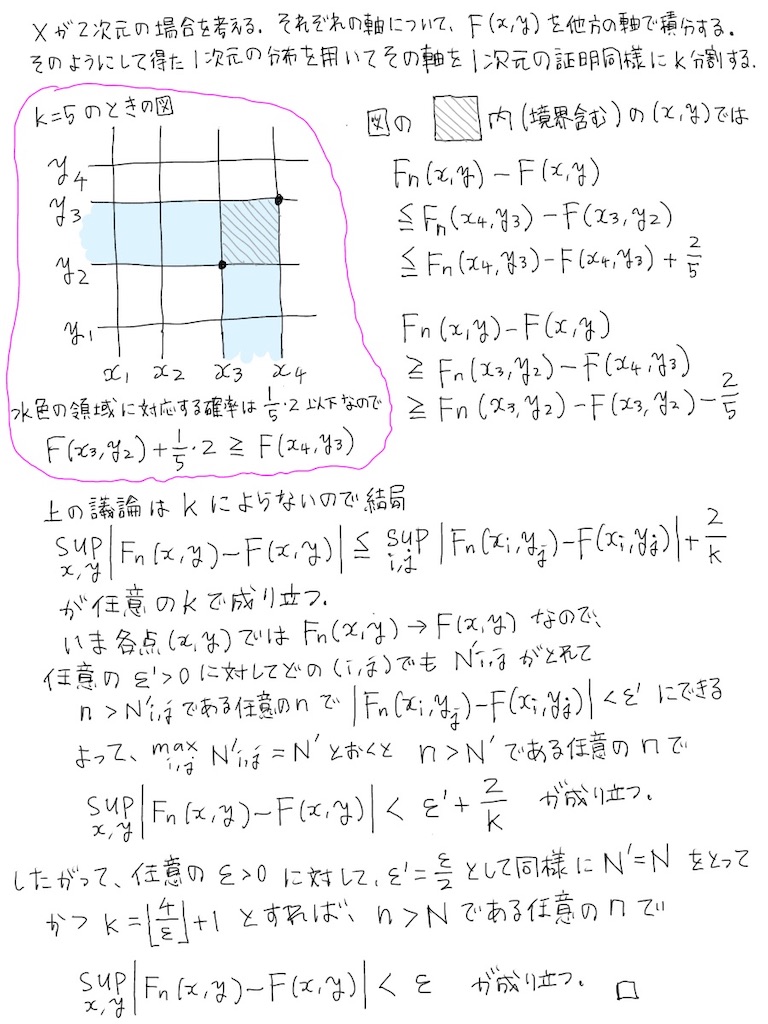
連続分布であれば、領域を 100 分割して、個々のエリアに対応する確率が 1/100 というようにできますね(連続分布でない場合はできる保証がありません)。そして、個々の領域での差

はどちらかの端っこでの差 + 1/100 で上から抑えられますね。各分割領域の端っこは有限個ですから、無限個の点の上での話(

)を、有限個(いまは99個)の点の上での話にできるわけです。99個の点を先に固定すれば、各点では収束しますから、すべての点での差の上界が十分小さくなるように
を大きくすることが可能です。任意の正数に応じて領域の分割数をじゅうぶん細かくして、何個かの点を固定して、
をじゅうぶん進めればよいですね。2次元以上の場合も同様の議論が可能です。上図で水色に塗っている領域は 2 × 1/5 で上から抑えられますが、d 次元であれば d × 1/5 で上から抑えられます。
終わり

